Search Engine Indexing
On This Page
When it comes to technical SEO making sure that search engines can crawl and index your site is #1 in importance. If your site can’t be crawled, it can’t be indexed and then people will never find it.
What Is Indexing?
After a page is discovered by Google, it tries to understand what the page is about and decides to add it to it’s “index”. Google’s index is just Google’s registry of all websites that they may want to show in their search results.
When you search on Google, you are not seeing all available websites that exist, you are only seeing websites Google has decided to add to their index of websites.
See If Google Can Index Your Site
After you have made sure Google can crawl your site, you’ll want to see if Google has indexed it as well. You can do this a few different ways.
Site Search
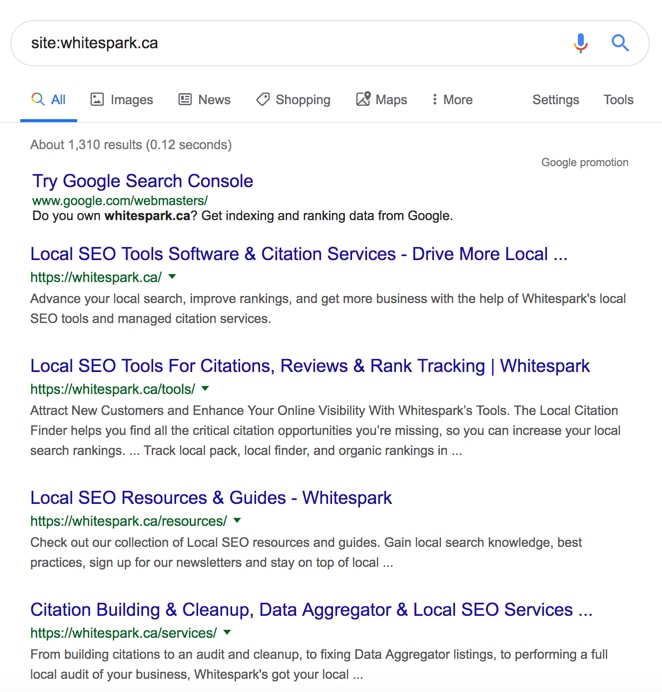
The quickest and easiest way to see if Google has indexed any of your site is to go to google.com and type in “site:domain.com” into the search bar. If you see any results then that means Google has indexed some or all of your pages.
Here’s what that would look like:
Google Search Console
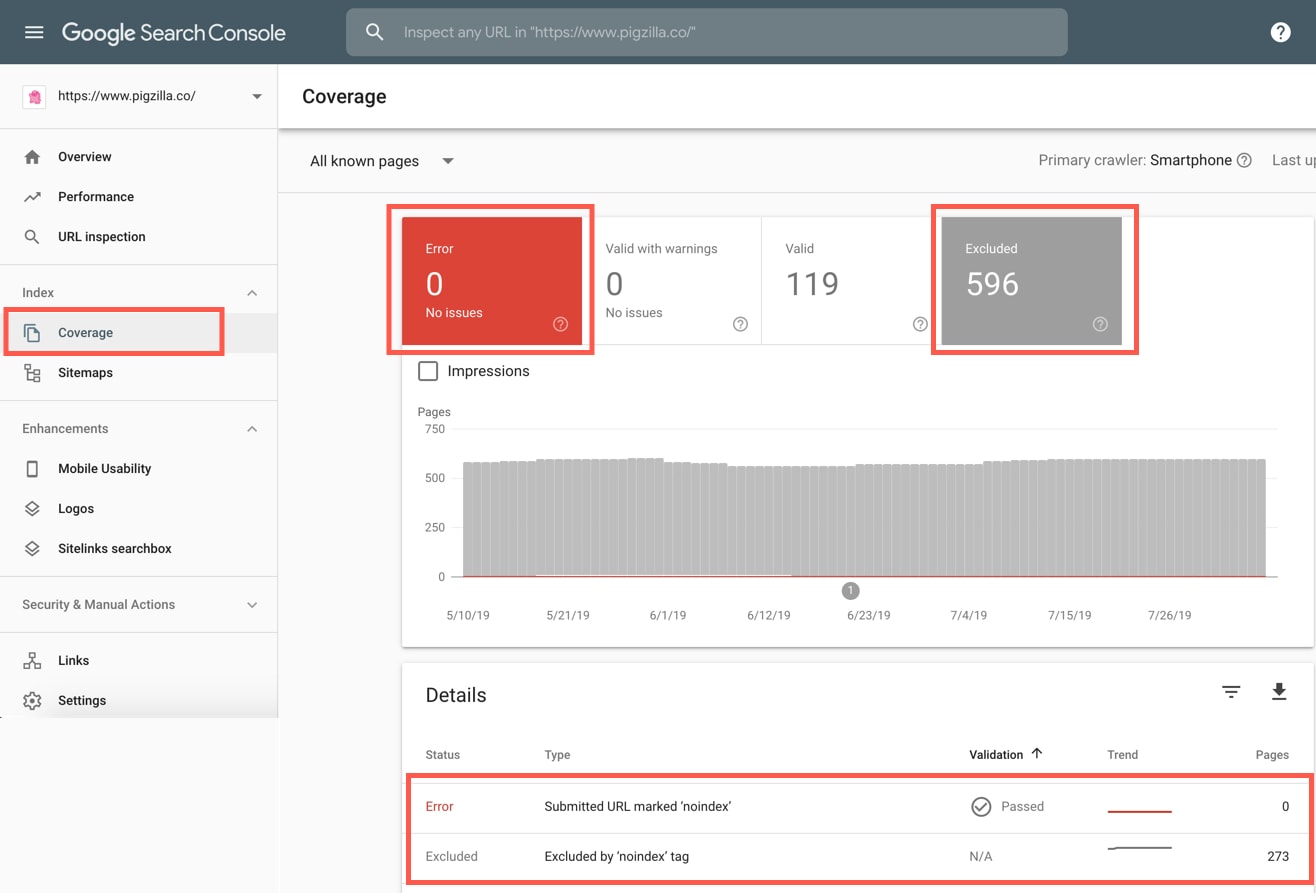
In Google Search Console go to the “Coverage” tab and select both the “Errors” and “Excluded” blocks. When you scroll down, if you see anything that says “noindex” this means Google is being told not to index those pages. Either on purpose or by accident.
Check The Meta Robots Tag
You can check the meta robots tag to see if the page is allowed to be indexed by search engines.
If you are using Chrome, right click and select “Inspect”. Then search for name=”robots”.
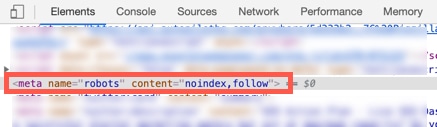
If you find no tag, then the page is allowed to be indexed.
If you find either of these tags, then the page in not allowed to be indexed.
<meta name=”robots” content=”noindex, follow”>
<meta name=”robots” content=”noindex, nofollow”>
Crawling Software
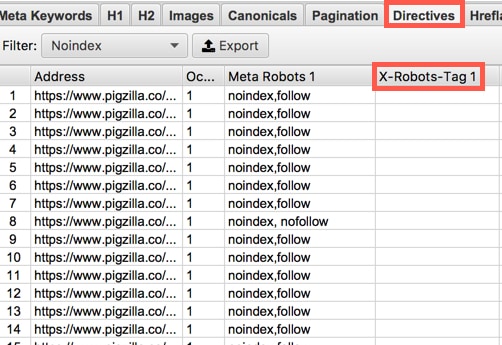
Another way you can see if pages are telling Google not to index them is by using a crawling software like ScreamingFrog as I mentioned before. You can crawl your site as Googlebot and check the “Directives” tab and look under the “Meta Robots” column. If any pages show the word “noindex” in the “Meta Robots” column then Google is being told not to index those pages.
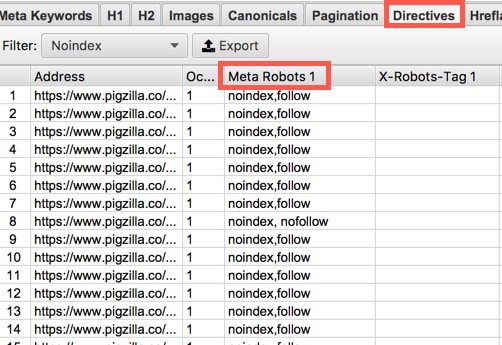
X-Robots-Tag
This is probably going to happen way less often on a small business website but I’ll cover it just incase. Another way you can noindex content is by an X-Robots-Tag. With this you can use robot.txt directives in the header of an HTTP response.
Checking in Chrome
You can see if a page has an X-Robots-Tag by looking at the HTTP headers of the page. If you are using Chrome, right click and select “Inspect”. Then click on the “Network” tab and reload the page. Select the HTTP request of the page and look for a X-Robots-Tag.
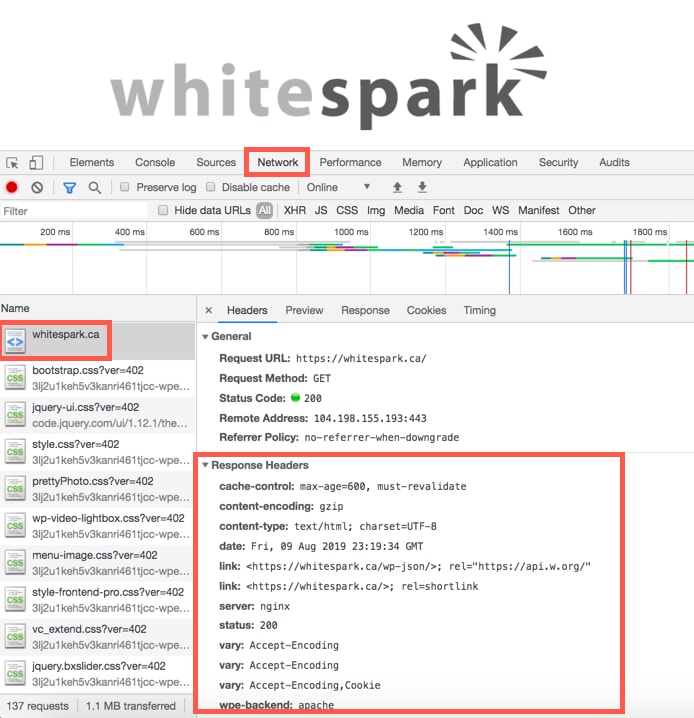
If you don’t see one then there obviously isn’t one. In the example above, there is none.
If you see something like this below then the page is being blocked from crawlers.
HTTP/1.1 200 OK
Date: Tue, 31 May 2019 21:42:43 GMT
(…)
X-Robots-Tag: noindex
(…)
HTTP/1.1 200 OK
Date: Tue, 31 May 2019 21:42:43 GMT
(…)
X-Robots-Tag: noindex, nofollow
(…)
Checking With a Crawling Software
Another way you can see if pages are being blocked by an X-Robots-Tag is to use a crawling software like ScreamingFrog. You can crawl your site as Googlebot and check the “Directives” tab and look under the “X-Robots-Tag” column.