Search Engine Crawling
On This Page
When it comes to technical SEO making sure that search engines can crawl and index your site is #1 in importance. If your site can’t be crawled, it can’t be indexed and then people will never find it.
What Is Crawling?
There isn’t a central registry of all web pages that exist anywhere (that we know of), so Google must constantly search for new pages and add them to its list of known pages. This process of discovery is called crawling.
Google uses a web crawler called Googlebot to crawl the internet. A web crawler is like a virtual robot or a spider. A web crawler is really just automated program that crawls from one web page to the next.
For example, Googlebot will crawl /about-us/ and if there are any links on the /about-us/ page to other pages, then Googlebot will crawl those next.
Why does Googlebot do this? If Googlebot finds new content, it may suggest that it be indexed by Google.
See If Google Can Crawl Your Site
You will need to see if Google is able to crawl your site. You can do this a few different ways.
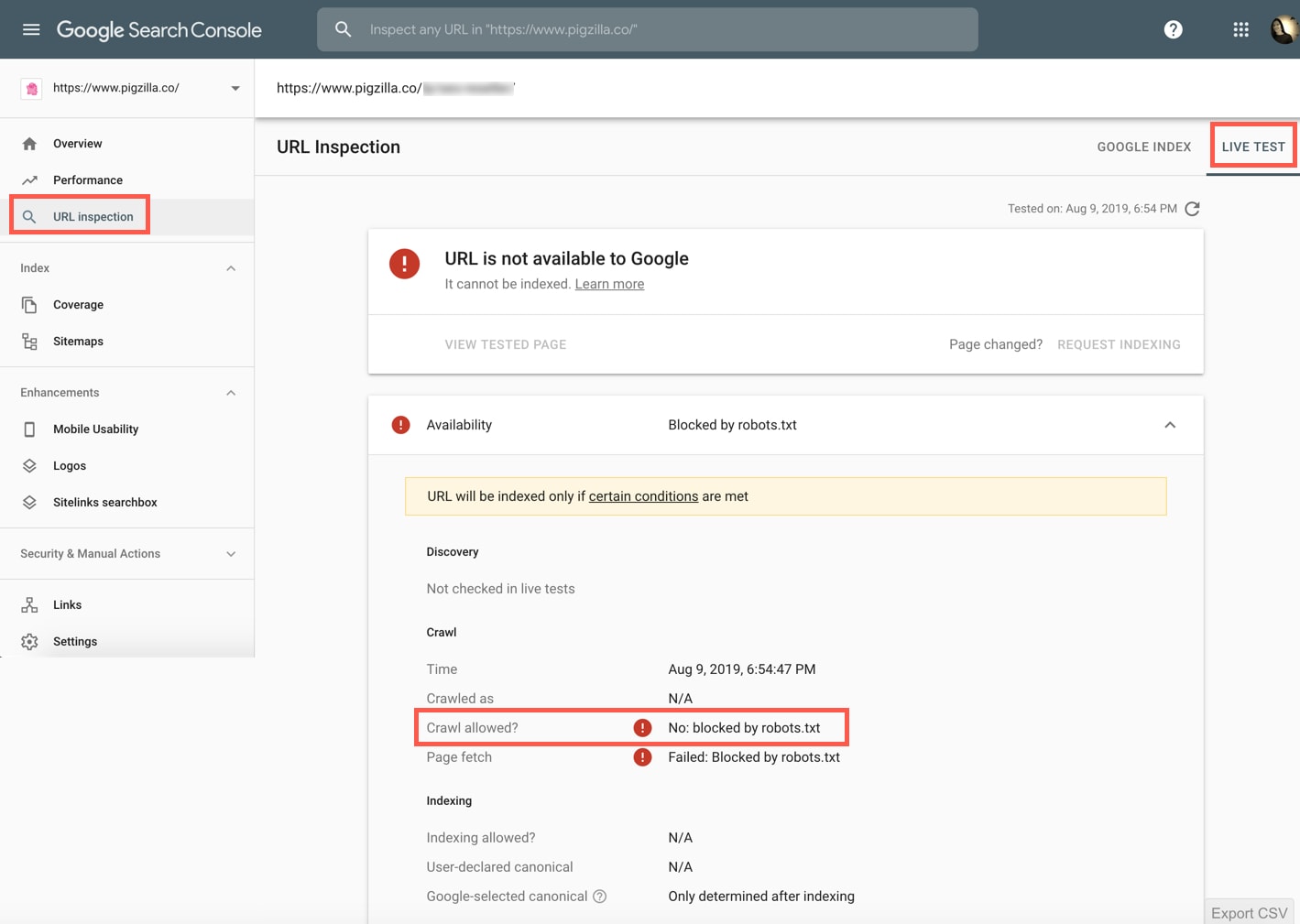
Google Search Console
Sign into Google Search Console and navigate to the “URL Inspection” tab. Enter the URL you want to test and then click on the “Test Live URL” button.
See what it says besides “Crawl allowed?” If it says: “No: blocked by robots.txt” then Google can’t crawl this page.
TechnicalSEO.com
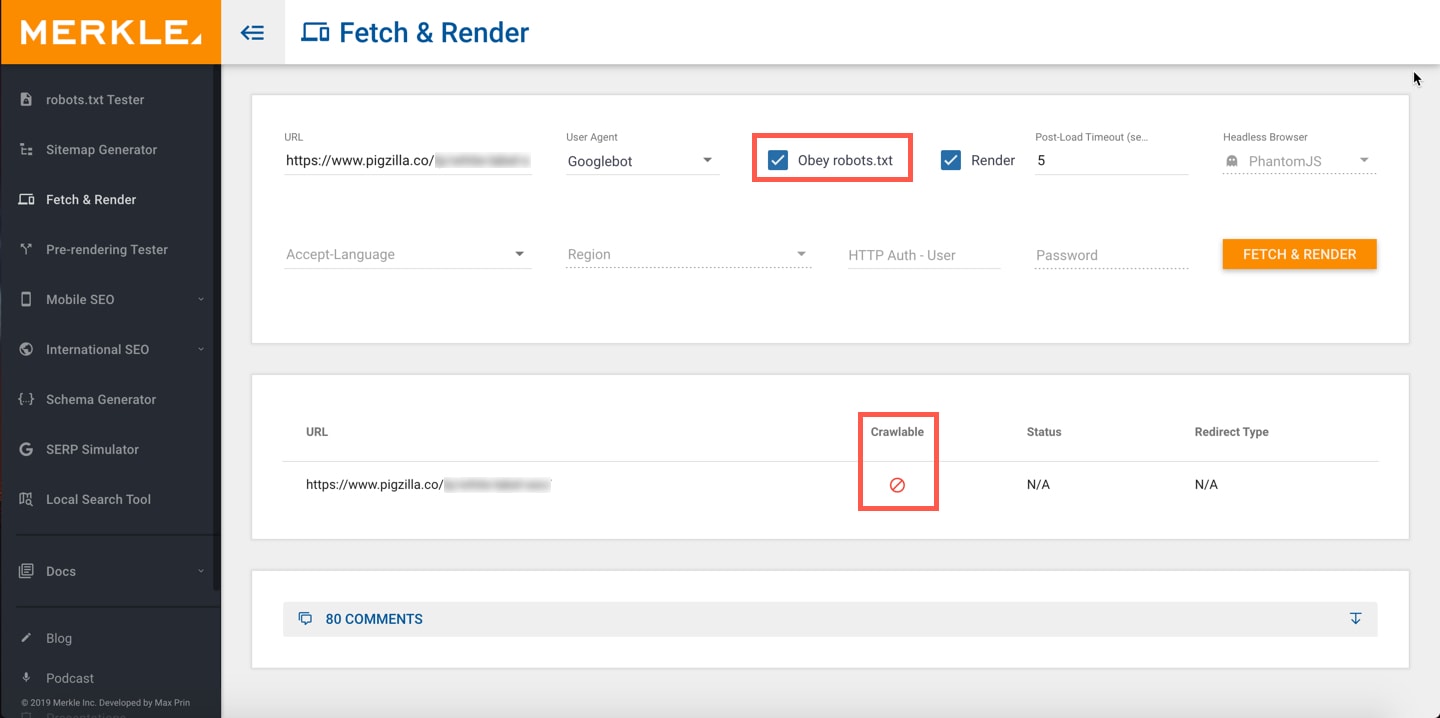
If you don’t have access to Google Search Console for some reason you can use this free Fetch & Render tool.
Make sure to check the “Obey robots.txt” box and click the “Fetch & Render” button. If the results show a “no symbol” like the screenshot below, then Google is not able to crawl this page.
Check Your Robots.txt File
Many times the reason Google can’t crawl your site is because it’s being blocked from doing so in the robots.txt file.
To view this file for your site, simply add /robots.txt to the end of your home page URL.
Example: https://www.pigzilla.co/robots.txt
There are a lot of ways this file can be configured but to keep it simple I’ll cover the two basic ways.
If your robots.txt file looks like this it’s blocking all web crawlers from all content on your site.
User-agent: *
Disallow: /
If your robots.txt file looks like this it’s allowing all web crawlers access to all content on your site.
User-agent: *
Disallow:
To learn more about robots.txt files, check out this article.